|
|
An R script for extracting durations from Praat text grids
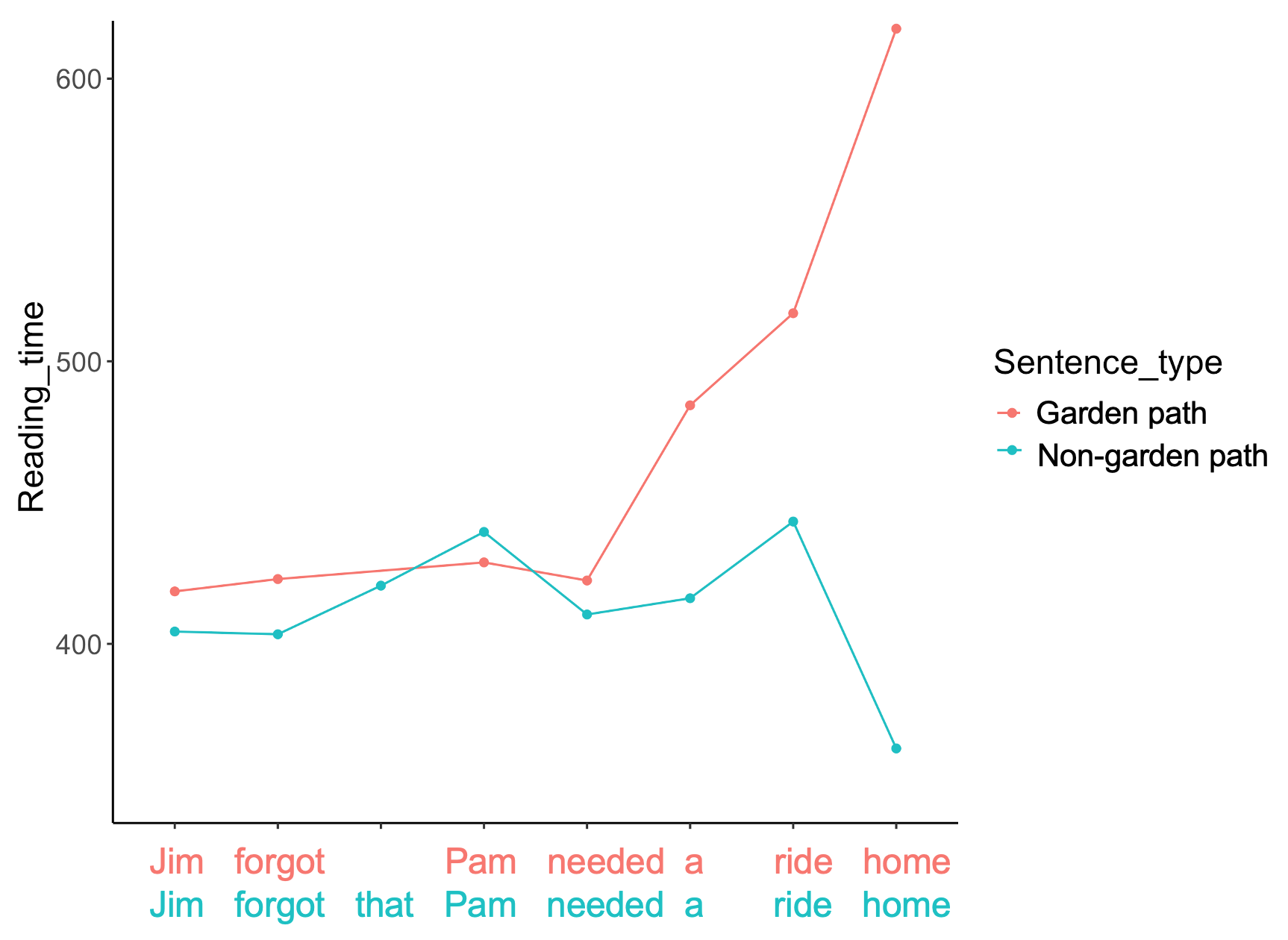
Praat is great for recording speech, and Praat scripting is a powerful tool for acoustic analysis. In sentence production research, Praat can be useful for analyzing participant responses. For example, sometimes we want to annotate sound files using TextGrids in order to extract timing information, like utterance duration, word duration, and pause duration, from participants' responses. Praat scripting can be used to automatically extract formant values, fundamental frequency, center of gravity, kurtosis, and many other wonderful acoustic properties (for more on acoustic analysis using Praat scripting, see here); Unfortunately, I wasn't able to find a Praat script that would simply extract the duration of labelled segments (say, the duration of every segment labelled "utterance length") from a bunch of TextGrids (though surely someone has written one). After trying (and failing) to adapt a Praat script that was originally designed to measure pause duration, I gave up and wrote a script in R. This script will pull out the duration of labelled segments from a bunch of TextGrids using the readtextgrid* package and some other data wrangling tools. The duration variables in this case are the duration between an auditory cue and the onset of speech ('beep-the'), the duration between an auditory cue and the onset of the first noun ('beep-N1'), and the full utterance duration ('full.sentence'). The script and sample Praat files can be found here. *Mahr T (2020). _readtextgrid: Read in a 'Praat' 'TextGrid' File_. R package version 0.1.1, <https://CRAN.R-project.org/package=readtextgrid>. An R script for processing Gorilla self-paced reading data Gorilla provides a tidy data file, but sometimes it's necessary to do some additional data wrangling before the data file is ready for analysis. For example, I recently did a self-paced reading experiment where I asked participants to read DO (double-object) datives (the man gave the girl a gift) and PO (prepositional object) datives (the man gave a gift to the girl). Each trial had two sentences: a context sentence, which was presented in segments of 3-6 words, and a test sentence, which was presented word by word. Gorilla assigns a number to each segment in a trial; however, the context sentences did not always have the same number of segments, so the numbering of the test sentence segments was not consistent across trials. To make matters worse, this analysis required test sentences to be divided into regions by phrase, not by individual word. So, all in all, some additional processing was necessary to clean up the data file, remove context sentences, and standardize the numbering of the segments in the test sentence. If your experiment requires a similar kind of processing, I hope this script will be useful. NOTE: part of the script splits the data by experimental condition. This is because the two sentence types (PO and DO) are different lengths, so they need to be numbered separately. Maybe you need to do this too, maybe not. You may need to remove/modify this section of the script along with updating all file paths. As always, if you have questions or if something doesn't work, please send me an email. Script here. Example trial here. A self-paced reading activity for introducing the garden-path effect NOTE: Unfortunately, Alex Drummond's Ibex Farm shut down on September 30th, 2021. Ibex experiments can still be run using PCIbex Farm, though the interface is slightly different. Eventually, I will update this page with instructions for running this activity using PC Ibex farm; in the meantime, the experiment files should still be usable if you wish to try it out yourself. In Fall 2020 I taught an undergraduate Introduction to Linguistics course, and during our unit on psycholinguistics we discussed the garden path effect and what it teaches us about how speakers process written sentences. Prior to introducing the garden path effect, I invited my students to complete an internet-based self-paced reading activity (really a short experiment) that featured stimuli from the self-paced reading study by Ferreira and Henderson (1990). After learning about the garden path effect, students were asked to discuss their experience completing the activity and predict what the results might be. We then visualized the students’ reading times, which indeed showed a slow-down at the disambiguation point in garden path sentences. Take a look at the visualization of the results. I wanted to do this activity mainly to show that the garden path effect was real, but it was also a nice way to introduce some of the research methods that are used in psycholinguistics. It also works well if you're using Language Files as your textbook, because the sentence processing section of the Psycholinguistics chapter includes some discussion of the garden path effect. The experiment was run using Ibex Farm and I analyzed the data/visualized the results using R. Since the experiment was conducted completely online, I simply posted the link to the course page on our learning management system and asked students to complete it if they wanted (I didn't grade them at all for this). If you want to do this activity yourself, you can import the experiment files directly to Ibex Farm. If you're using the old Ibex Farm, you can import the experiment files using the git import feature. Use git repo URL 'https://github.com/jweiric/GardenPath' with the branch/revision set to 'Files'. If you're using the new Ibex farm, simply download the experiment files and then drag and drop the main folder onto the folder icon next to the experiment name. The R script that I used to analyze/visualize the results can be found here. Please feel free to use these files and modify them as you see fit. If something isn't working, PLEASE email me and let me know. I'll feel very bad if someone can't do this activity because something isn't working. Introduction to Ibex Tutorial This tutorial provides a brief introduction to Alex Drummond's Internet Based Experiments (Ibex). It is intended for those who have no experience using Ibex. Using a short acceptability judgement task as an example, the tutorial discusses the basic structure of an Ibex experiment and the data_includes file, and introduces key concepts like variables, controllers, and options. Common options for the Question and AcceptabilityJudgement controllers are explored. See the tutorial handout here. |
{kind=link}
{kind=link}